Table of Contents
Open Table of Contents
Time to Build Our Own Dataset
The first step to build the dataset is to find a good source of information. Fandom seems to be the perfect source for this project, even if the data is unparsed. Now to parse the data.
The work from Kaggle Dataset gathers information from the list of characters. My goal is to gather more information for my dataset.
Using Beautiful Soup
Beautiful Soup, aka, Bs4, is a Python package used for webscraping. Since Fandom has no working API, we will manually parse info from the frontend.
This is what we see on the Character list page:
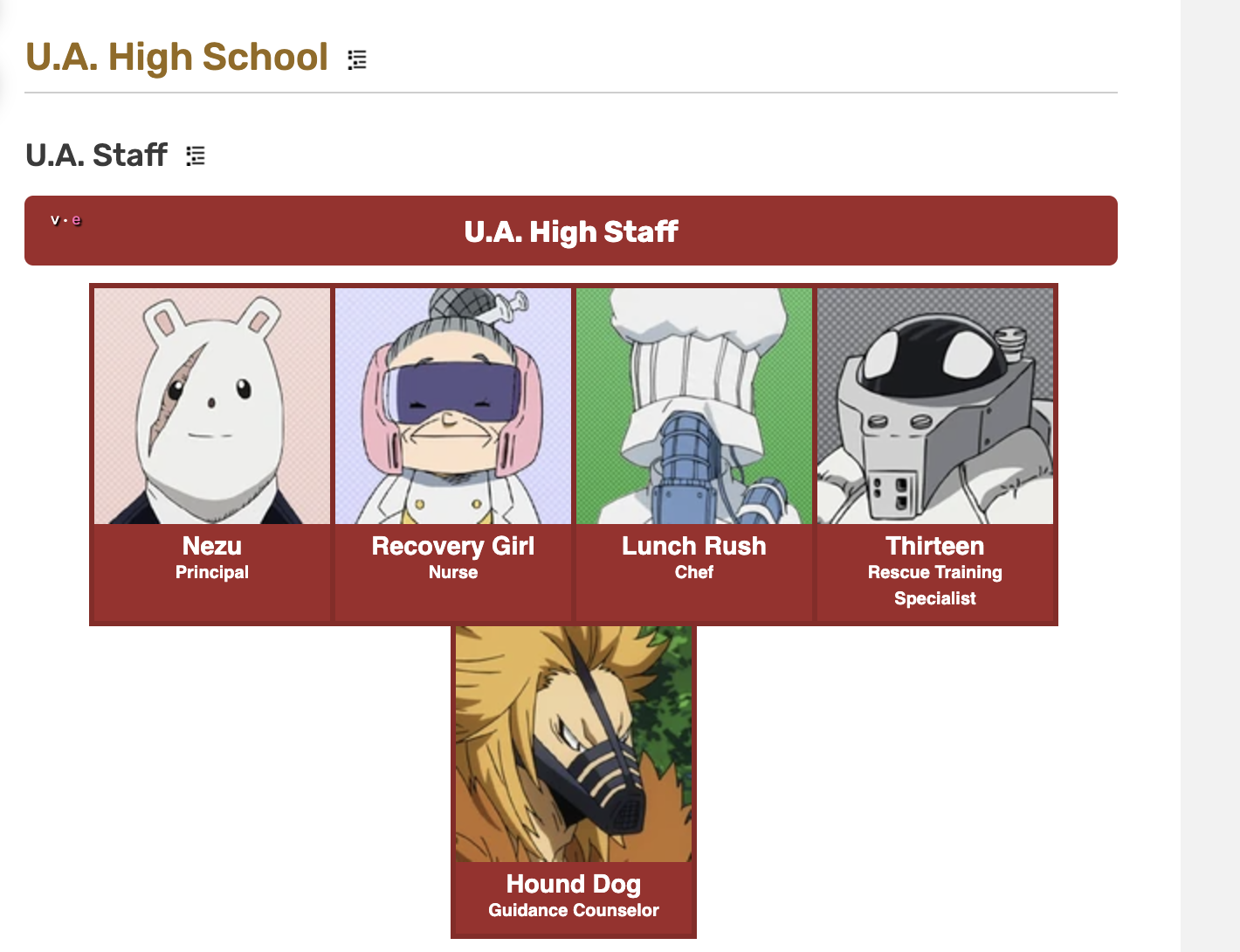
Reading the code directly from inspecting the browser, we can see that the character galleries are between h2 tags. This is the first thing the script does, get the data between h2s. The result is just a bunch of unreadable garbage that will be used later.
# Building upon https://www.kaggle.com/code/birlinha/data-mining-boku-no-hero-my-hero-academia
from bs4 import BeautifulSoup, NavigableString
from rich import print as richprint
import requests
url = 'https://myheroacademia.fandom.com/wiki/List_of_Characters'
html_data = requests.get(url)
soup = BeautifulSoup(html_data.text, 'html.parser')
h2_tags = soup.find_all('h2')
new_soups = []
# Find content between h2 tags
for i in range(len(h2_tags) - 1):
# Get the text between the current h2 and the next h2
text_between_h2s = []
next_tag = h2_tags[i + 1]
for sibling in h2_tags[i].find_next_siblings():
if sibling == next_tag:
break
if isinstance(sibling, NavigableString):
text_between_h2s.append(str(sibling).strip())
else:
text_between_h2s.append(str(sibling))
# Create a new soup with the text between the h2 tags
new_soup = BeautifulSoup(''.join(text_between_h2s), 'html.parser')
new_soups.append(new_soup)
richprint(new_soups)
After some more inspection, we can see that each gallery is numbered quite arbitrarily if you ask me, but each one has an attribute “id” with a value “gallery-{i}” where i is a number. With i=100 we can get all of the information. Relevant to extract from this page is: The character name, the image URL, and the character URL in Fandom (to extract the remaining information).
galleries_element_list = []
people_info = []
name_list = []
for s in new_soups:
for i in range(0, 100): # 100 is arbitrary
pat_gal = f"gallery-{i}" # Items
gallery = s.find("div", attrs={"id": pat_gal})
if gallery:
galleries_element_list.append(gallery)
for g in galleries_element_list:
people = g.find_all(name="div", attrs={"class": "wikia-gallery-item"})
for person in people:
chargallery_prof = person.find(name="div", attrs={"class": "chargallery-profile-caption"})
href_person = chargallery_prof.find(name="a").get("href")
name = chargallery_prof.find(name="a").text
img = person.find("img").get("src")
img_url = img.split("/revision/")[0]
if name not in name_list: # Prevent duplicates
people_info.append({"name": name, "href_person": href_person, "img_url": img_url})
name_list.append(name)
richprint(people_info)
Getting Character Attributes
Now that we have the base character information, we can start working on the details about each character. To simplify everything, we create a class to hold the information. This class is based on an SQL model (which is a combination of Pydantic and SQLAlchemy). This has several advantages:
- No need to create a constructor for the class;
- Built-in serialization with the method model_dump();
- Database support (as it is an SQLAlchemy object);
The initial idea for this script was to send this data to a database. Using the SQLModel, we just need to add __tablename__ as a property.
Note: The attributes in the class were created by making a first run of all the characters and listing the attributes (This is not the first version of this script ;))
from sqlmodel import SQLModel, Field, Column, String, ARRAY
from typing import Optional
class PeopleAtts(SQLModel, table=True):
__tablename__= "people_atts"
id: int | None = Field(default=None, primary_key=True)
href_person: str | None = Field(default=None)
img_url: str | None = Field(default=None)
occupation: list[str] | None = Field(sa_column=Column(ARRAY(String)))
quirk: list[str] | None = Field(sa_column=Column(ARRAY(String)))
manga_debut: str | None = Field(default=None)
romaji_name: str | None = Field(default=None)
quirk_range: str | None = Field(default=None)
real_name: str | None = Field(default=None)
eye_color: str | None = Field(default=None)
english_va: list[str] | None = Field(sa_column=Column(ARRAY(String)))
gender: str | None = Field(default=None)
teams: list[str] | None = Field(sa_column=Column(ARRAY(String)))
birthday: str | None = Field(default=None)
participants: str | None = Field(default=None)
located_in: str | None = Field(default=None)
status: str | None = Field(default=None)
leaders: str | None = Field(default=None)
user: str | None = Field(default=None)
location: str | None = Field(default=None)
japanese_name: str | None = Field(default=None)
blood_type: str | None = Field(default=None)
alias: str | None = Field(default=None)
skin_color: str | None = Field(default=None)
other_members: str | None = Field(default=None)
epithet: str | None = Field(default=None)
hair_color: str | None = Field(default=None)
movie_debut: str | None = Field(default=None)
height: str | None = Field(default=None)
japanese_va: list[str] | None = Field(sa_column=Column(ARRAY(String)))
quirk_type: str | None = Field(default=None)
anime_debut: str | None = Field(default=None)
fighting_style: list[str] | None = Field(sa_column=Column(ARRAY(String)))
vigilantes_debut: str | None = Field(default=None)
age: list[str] | None = Field(sa_column=Column(ARRAY(String)))
kanji_name: str | None = Field(default=None)
weight: str | None = Field(default=None)
leader: str | None = Field(default=None)
family: list[str] | None = Field(sa_column=Column(ARRAY(String)))
birthplace: str | None = Field(default=None)
affiliation: list[str] | None = Field(sa_column=Column(ARRAY(String)))
anime_debut_arc: str | None = Field(default=None)
Visiting the character page, I am presented with:
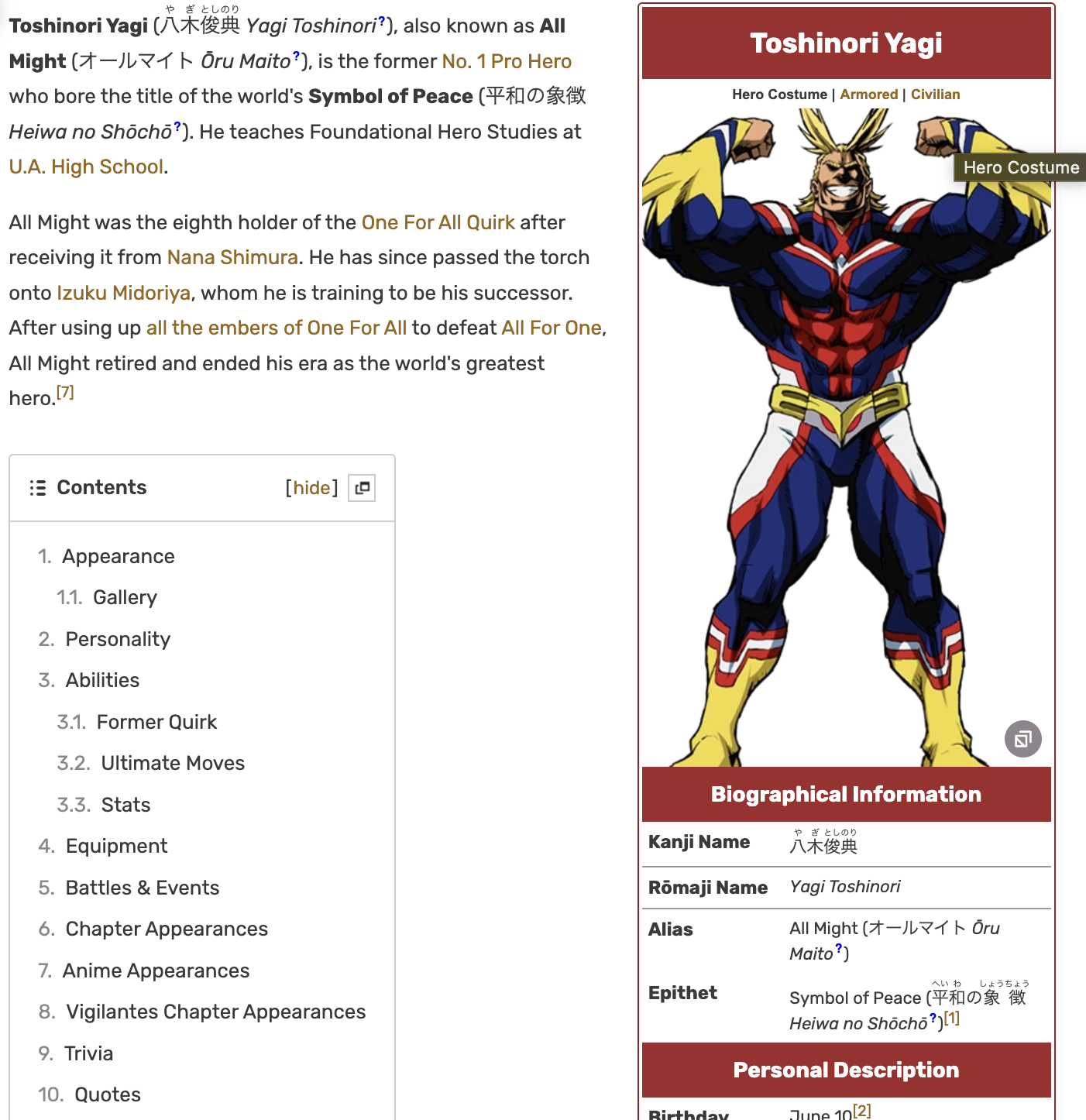 We need to get the gallery on the bottom right and parse its information. This process is similar to what I did before. In this case, I first parse the “aside” portion of the game and then parse the information corresponding to the tags “pi-data-label” and “pi-data-value”. This is a 1-1 match, so there is no need to fix edge cases here.
We need to get the gallery on the bottom right and parse its information. This process is similar to what I did before. In this case, I first parse the “aside” portion of the game and then parse the information corresponding to the tags “pi-data-label” and “pi-data-value”. This is a 1-1 match, so there is no need to fix edge cases here.
Notes regarding parsing:
- For anime debut, I am actually interested in the link of the episode, not the name of the episode itself (used later);
- For height, I want 172 from 172cm (…), and therefore I use a regex match;
- For lists, I use
stripped_stringsinstead of text (which automatically joins the text); - For alias, I just use the first element of the list;
- For affiliation, occupation, teams, family, fighting_style, english_va, japanese_va, quirk, I use the list strategy;
- For the remainder, I use the
.textmethod.
import re
BASE_URL = "https://myheroacademia.fandom.com"
def transform_atts(name, img_url, href_person):
global counter, total
data_html = requests.get(BASE_URL + href_person)
soup = BeautifulSoup(data_html.text, 'html.parser')
aside = soup.find("aside")
pi_label = aside.find_all("h3", {"class": "pi-data-label"})
pi_val = aside.find_all("div", {"class": "pi-data-value"})
new_label = [item.text.replace(' ', '_').replace('(', '').replace(')', '').replace('ō', 'o').lower() for item in pi_label]
pre_parsed_pi = dict(zip(new_label, pi_val))
parsed = {'real_name': name, 'img_url': img_url, 'affiliation': None, 'occupation': None, 'teams': None, 'family': None, 'fighting_style': None, 'japanese_va': None, 'english_va': None, 'quirk': None}
for k, v in pre_parsed_pi.items():
if k == 'anime_debut':
a_tags = v.find_all('a')
if a_tags:
parsed[k] = a_tags[-1].get('href')
else:
parsed[k] = v.text
elif k == 'height': # Parse height to only get the number
matches = re.findall(r"\b\d{2,3}\s?cm\b", v.text)
parsed[k] = matches[0].replace(' ', '')[:-2] if matches else v.text
elif k in ['alias']: # Only get the first element
clean = [s for s in v.stripped_strings if '(' not in s and ')' not in s and '[' not in s and ']' not in s]
parsed[k] = clean[0] if clean else None
elif k in ['affiliation', 'occupation', 'teams', 'family', 'fighting_style', 'japanese_va', 'english_va', 'quirk']:
parsed[k] = [s for s in v.stripped_strings if '(' not in s and ')' not in s and '[' not in s and ']' not in s]
else: # Get text instead of array form
cleaned_text = re.sub(r'\[\d+\]|\([^)]*\)', '', v.text) # Remove [1] and (text)
parsed[k] = cleaned_text.strip()
if parsed.get("age") is not None:
parsed["age"] = parsed.get("age").split(' ')
richprint(f"Transformed {parsed.get('real_name')} - {counter} of {total}")
return PeopleAtts(href_person=href_person, **parsed)
Adding Arc Information
To add the arc information, I use a similar strategy as the one used to get character info, using the episode info collected in anime_debut. Each episode page looks like this:
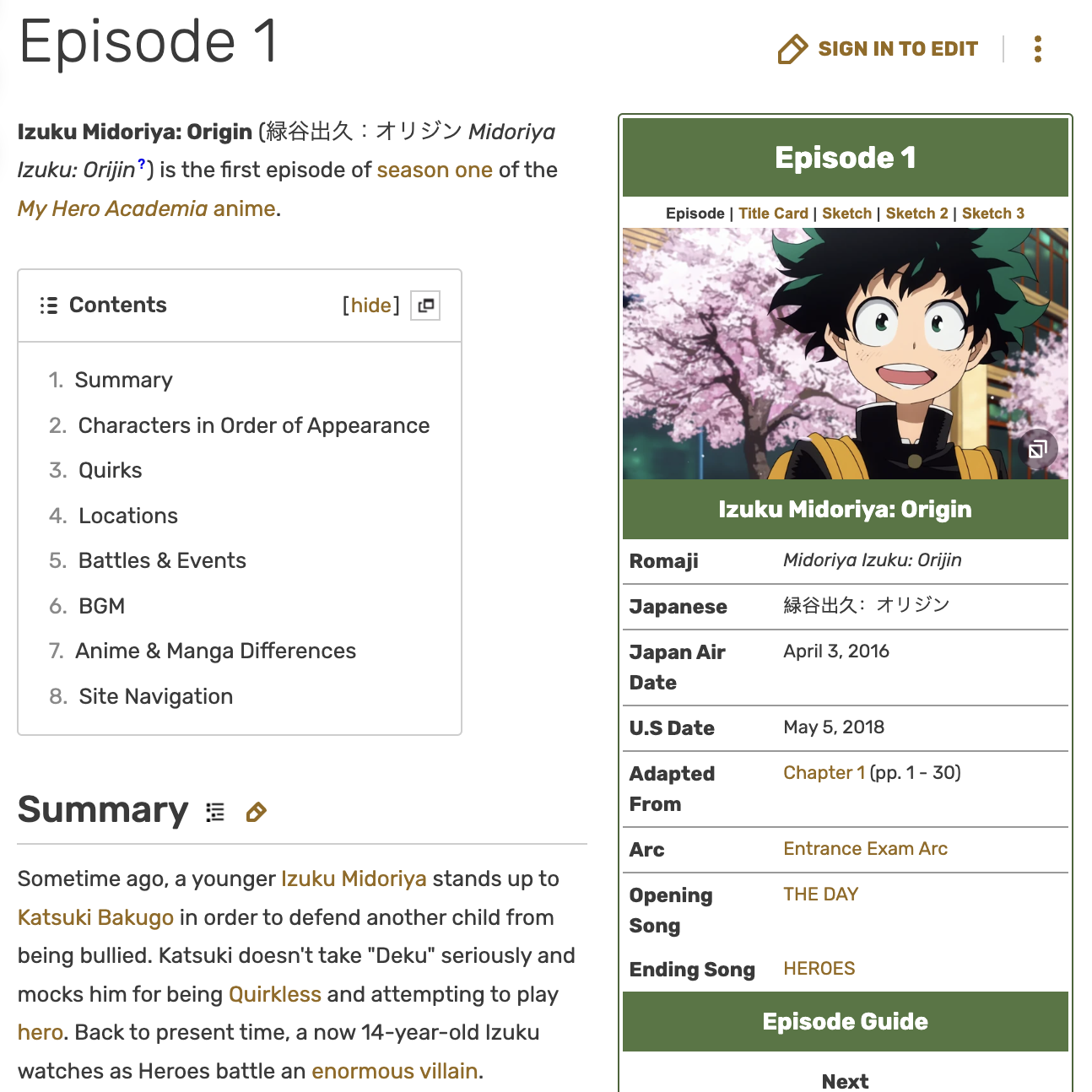
Very importantly, there is an arc pi_property (in the image “Entrance Exam Arc”). I also found some edge cases where there are episodes with multiple arcs. For consistency, I select the first one (as I do in alias).
def _add_arc(epi_name): # Fix for multiple arcs
arc_url = BASE_URL + '/wiki/' + epi_name if not epi_name.startswith('/wiki/') else BASE_URL + epi_name
data_html = requests.get(arc_url)
soup = BeautifulSoup(data_html.text, 'html.parser')
aside = soup.find("aside")
pi_label = aside.find_all("h3", {"class": "pi-data-label"})
pi_val = aside.find_all("div", {"class": "pi-data-value"})
new_label = [item.text.replace(' ', '_').replace('(', '').replace(')', '').replace('ō', 'o').lower() for item in pi_label]
pre_parsed_pi = dict(zip(new_label, pi_val))
parsed = {}
for k, v in pre_parsed_pi.items():
if k == 'arc':
clean = [s for s in v.stripped_strings if '(' not in s and ')' not in s and '[' not in s and ']' not in s]
parsed[k] = clean[0] if clean else None # Some episodes have multiple arcs so we only get the first one
else:
cleaned_text = re.sub(r'\[\d+\]|\([^)]*\)', '', v.text) # Remove [1] and (text)
parsed[k] = cleaned_text.strip()
return parsed.get("arc", None)
I also update the transform_atts function with this information:
if parsed.get("anime_debut") is not None:
#print(f"Parsing anime debut {parsed.get('anime_debut')}")
parsed["anime_debut_arc"] = _add_arc(parsed.get("anime_debut"))
To run the full project, we just need to put the entire thing together (check and run the file):
pp_list = {}
for char in people_info:
if char.get('name') is not None:
pp_list[char['name']] = transform_atts(char.get('name'), char.get('img_url'), char.get("href_person")).model_dump()
richprint(pp_list)
Post Processing
After doing all this, one might think this is it, but no. I had to fix some things manually (which took like 2 minutes and wasn’t really worth automating), ensuring that occupation and affiliation are correct.
For this, I created a mini script that prints all the affiliation and occupation (I could verify everything else, but I am only interested in a subset of the attributes) and fix the names that have something wrong (extra comma, removing “Leader of the” and such).
import json
from models.people import PeopleAtts
from rich import print as richprint
def fix_people_data(path):
# Do manual verification
data = json.load(open(path))
char = {k: PeopleAtts(**v) for k, v in data.items()}
test = set()
for k, v in char.items():
if v.affiliation is not None:
for aff in v.affiliation:
test.add(aff)
richprint(test)
richprint('----------------')
test2 = set()
for k, v in char.items():
if v.occupation is not None:
for aff in v.occupation:
test2.add(aff)
richprint(test2)
fix_people_data('filtered_people.json')